Openshift Origin - Gear process hangs and ps as root also hangs
Background
A few months ago we installed openshift origin cluster in a few of our servers. We have tried openshift M3 with good results. Upgrading to M4 and deploying several live apps there, we found gears that hangs each week or two, that cannot be resolved by stopping and starting the gear. After the third time this is getting troublesome.
Symptoms
- Application URL doesn't respond
- haproxy-status URL shows gears in red status before eventually hangs itself
- Full processlist done by root in the node will hang when the process in question is being printed
Investigation
Before we understood the root cause, restarting the VM is sometimes the only solution if the problem occurs. Strace-ing the hanging ps shows that ps is stopped when trying to read some memory.
A few instances of the problem 'heals' by itself after one day.
In some instances killling the process with the cmdline anomaly will solve the problem.
The real eye opening is the blog post Reading /proc/pid/cmdline could hang forever. It never occured to me that Openshift Origin disables kernel out of memory mechanism for its gears, which when in effect, suspends the task/process that triggers the out of memory condition for the cgroups. The keyword is cgroup memory control.
Reconstruction
First lets watch the cgroup memory status. Under /cgroup/memory we have folders, we are interested in files named memory.oom_control because these files have additional line that shows whether out-of-memory (oom) condition is happening.
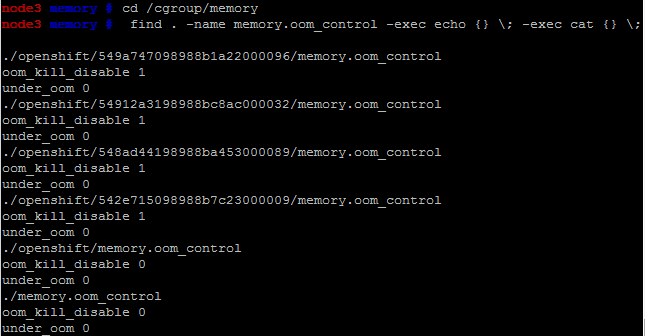 |
| Monitoring OOM condition from root console |
Lets try to consume memory. I choose to use rhc ssh to connect to the gear and from bash, executes a loop that consumes memory. I used this script I found in an StackOverflow post.
A="0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef"
for power in $(seq 8); do
A="${A}${A}"
donefor power in $(seq 8); do
A="${A}${A}"
done
for power in $(seq 8); do
A="${A}${A}"
done
Meanwhile, check for OOM condition from root console. When OOM occured, the rhc ssh session would hang and under_oom flag would be 1.
 |
| under_oom flag is now 1 |
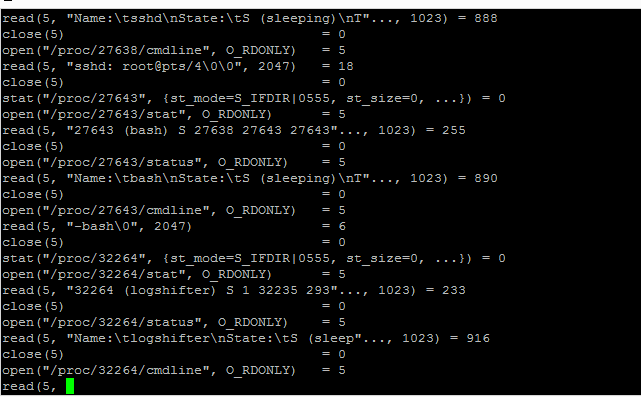 |
| strace ps auxw, hangs in root console |
 |
| ps -u works but ps -u -f hangs |
Sometimes ^C works, sometimes it doesn't. Now this is a dangerous condition. Lets reenable OOM killer and allows us to proceed.

The var/log/messages show us the result of reenabling the OOM killer :
Dec 28 23:39:11 node3 kernel: 3687037 total pagecache pages
Dec 28 23:39:11 node3 kernel: 9138 pages in swap cache
Dec 28 23:39:11 node3 kernel: Swap cache stats: add 549704, delete 540566, find 268368/295738
Dec 28 23:39:11 node3 kernel: Free swap = 33397076kB
Dec 28 23:39:11 node3 kernel: Total swap = 33554428kB
Dec 28 23:39:12 node3 kernel: 4194288 pages RAM
Dec 28 23:39:12 node3 kernel: 111862 pages reserved
Dec 28 23:39:12 node3 kernel: 2181578 pages shared
Dec 28 23:39:12 node3 kernel: 1915782 pages non-shared
Dec 28 23:39:12 node3 kernel: [ pid ] uid tgid total_vm rss cpu oom_adj oom_score_adj name
Dec 28 23:39:12 node3 kernel: [32264] 6248 32264 65906 998 5 0 0 logshifter
Dec 28 23:39:12 node3 kernel: [32265] 6248 32265 5571 436 9 0 0 haproxy
Dec 28 23:39:12 node3 kernel: [32266] 6248 32266 2834 257 8 0 0 bash
Dec 28 23:39:12 node3 kernel: [32267] 6248 32267 49522 1563 6 0 0 logshifter
Dec 28 23:39:12 node3 kernel: [32281] 6248 32281 11893 1993 1 0 0 ruby
Dec 28 23:39:12 node3 kernel: [32368] 6248 32368 150982 4796 4 0 0 httpd
Dec 28 23:39:12 node3 kernel: [32369] 6248 32369 65906 1102 6 0 0 logshifter
Dec 28 23:39:12 node3 kernel: [32378] 6248 32378 1018 117 5 0 0 tee
Dec 28 23:39:12 node3 kernel: [32379] 6248 32379 1018 113 7 0 0 tee
Dec 28 23:39:12 node3 kernel: [32380] 6248 32380 152662 4506 6 0 0 httpd
Dec 28 23:39:12 node3 kernel: [32381] 6248 32381 152662 4504 0 0 0 httpd
Dec 28 23:39:12 node3 kernel: [ 8297] 0 8297 27799 1691 1 0 0 sshd
Dec 28 23:39:12 node3 kernel: [ 8304] 6248 8304 27799 1021 0 0 0 sshd
Dec 28 23:39:12 node3 kernel: [ 8305] 6248 8305 174666 112273 8 0 0 bash
Dec 28 23:39:12 node3 kernel: [ 9207] 6248 9207 150982 1839 7 0 0 httpd
Dec 28 23:39:12 node3 kernel: Memory cgroup out of memory: Kill process 8305 (bash) score 917 or sacrifice child
Dec 28 23:39:12 node3 kernel: Killed process 8305, UID 6248, (bash) total-vm:698664kB, anon-rss:447584kB, file-rss:1508kB
Check the oom condition :
node3 542e715098988b7c23000009 # cat memory.oom_control
oom_kill_disable 0
under_oom 0
node3 542e715098988b7c23000009 #
We can see that under_oom has returned to 0. After that, I tried ps auxw as root and it doesn't hang anymore.
Conclusion
The hanging of the root console seem to be unexpected side effect of memory cgroups that supposed to suspend the application under cgroup, but also suspends other tasks that tried to access the app's memory as well.
When this condition happened, the solution is to either reenable the oom killer (as being demonstrated above) or to increase memory limit. Both steps will resume the suspended task and prevent other tasks from hanging. It turns out that these exactly what openshift watchman does, increase memory limit for 10%, and restart the gear. The logic is in the oom_plugin.
The reason that this happened is because watchman is not running. That is strange, because the installation team precisely followed the Openshift Comprehensive Deployment Guide. It seems that the guide missing the steps to enable watchman service.

Comments