Openshift Origin - Gear process hangs and ps as root also hangs
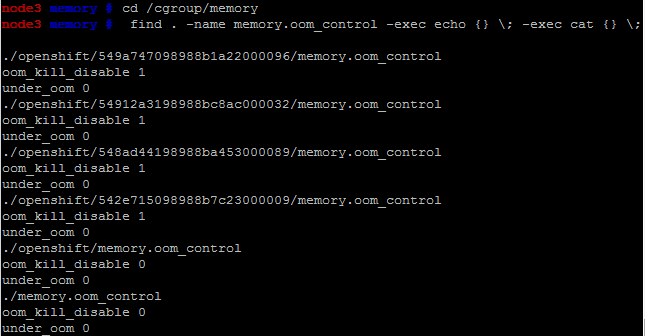
Background A few months ago we installed openshift origin cluster in a few of our servers. We have tried openshift M3 with good results. Upgrading to M4 and deploying several live apps there, we found gears that hangs each week or two, that cannot be resolved by stopping and starting the gear. After the third time this is getting troublesome. Symptoms - Application URL doesn't respond - haproxy-status URL shows gears in red status before eventually hangs itself - Full processlist done by root in the node will hang when the process in question is being printed Investigation Before we understood the root cause, restarting the VM is sometimes the only solution if the problem occurs. Strace-ing the hanging ps shows that ps is stopped when trying to read some memory. A few instances of the problem 'heals' by itself after one day. In some instances killling the process with the cmdline anomaly will solve the problem. The real eye opening is the blog post...