Testing your web app with Selenium
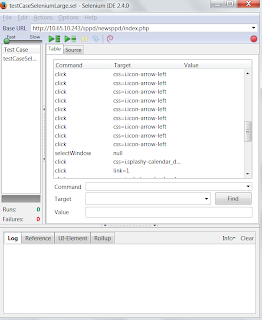
Selenium is a web testing toolkit. This week I tried to use Selenium tools to create a test scenario that actually automates the web browser in order to populate test database. Similar to many open source tools, it has its rough edges. My first problem is automating the jquery UI datepicker. Recording with Selenium IDE gives a result that is not too reliable : It isn't easy to change the month or day in this test script. Running this script failed with error message that Selenium couldn't find the '1' link. The '1' is actually a clickable td but the script assumed it was a HTML link (a tag). Finding other sources, I replaced the last row with click css=td.day:contains("1"). Which sometimes doesn't work correctly because sometimes it choose the 31 cell instead of 1 cell. After a while I settled by a runScript command that invokes jQuery to set the datepicker value : runScript $("Request_kembali").val("2013-01-01"); The...